


Connection Pool
Como reducir el costo de las conexiones y operaciones entre una aplicación y una dependencia


Una buena conectividad entre aplicaciones es fundamental para que funcionen correctamente.
Tener un Connection Pool bien definido y configurado ayuda con este problema.
Hoy vamos a ver:
¿Qué es una conexión y por qué es necesaria para acceder a una dependencia?
¿Como funciona una conexión?
¿Qué desafíos se presentan al manejar múltiples conexiones simultáneas?
¿Qué es un Connection Pool y cómo nos puede ayudar a manejar múltiples conexiones simultáneas?
¿Como funciona un Connection Pool?
¿Qué ventajas y desventajas tiene usar un Connection Pool?
¿Cuales son los errores mas comunes al usar un Connection Pool?
¿Como definir el tamaño optimo de un Connection Pool y qué factores hay que tener en cuenta?
Conclusiones
¿Qué es una conexión y por qué es necesaria para acceder a una dependencia?
Una conexión es un canal de comunicación entre una aplicación y una dependencia (base de datos, cache o servicio externo).
Este canal nos permite enviar consultas, recibir resultados y realizar operaciones con los datos.
¿Como funciona una conexion?
Existen diferentes tipos de conexiones y protocolos.
Voy a utilizar como ejemplo una conexión TCP, ya que es uno de los protocolos mas utilizados, sobre todo para navegar por internet (HTTP/HTTPS), correo electrónico (SMTP, IMAP, POP3), transferencia de archivos (FTP) y conectarse a bases de datos (Redis, PostgreSQL, MySQL, MongoDB).
Generalmente la mayoría de las aplicaciones necesitan conexiones persistentes y este protocolo tiene la capacidad para proporcionar una entrega de datos fiable.
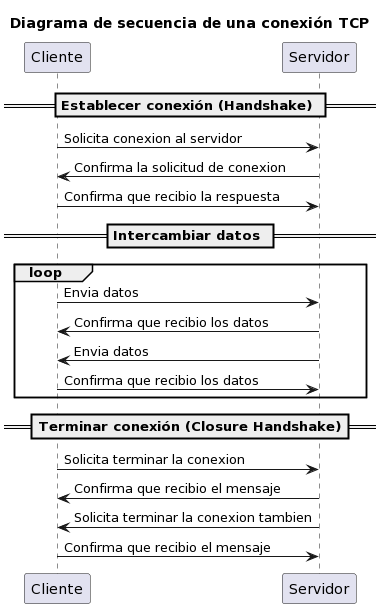
Una conexión TCP tiene 3 fases:
Fase 1: Establecimiento de la conexión, también conocido como Handshake, donde el cliente y el servidor negocian los detalles de la conexión.
Fase 2: Intercambio de datos, el cliente envía los datos que necesita al servidor y el servidor confirma que recibe los datos al cliente. Cuando el cliente recibe la confirmación de que los datos fueron recibidos, envía mas información, sino, reintenta el envío de los datos. Es por eso que se considera un protocolo confiable para enviar datos.
Fase 3: Terminación de la conexión, también conocido como Closure Handshake, donde tanto el cliente como el servidor se avisan mutuamente que van a dejar de enviar datos.
Aqui te comparto un diagrama de sequencia de alto nivel mostrando las 3 fases.
¿Qué desafíos se presentan al manejar múltiples conexiones simultáneas?
Una aplicacion suele usar varias conexiones contra sus dependencias.
Tener varias conexiones le permite realizar consultas en paralelo y obtener la información mas rápido para devolverla a los usuarios lo antes posible.
Algunos de los desafíos mas comunes al manejar varias conexiones simultaneas son los siguientes:
Recursos Disponibles
Cada conexión consume memoria, CPU y ancho de banda, lo que puede afectar al rendimiento y la disponibilidad de una dependencia.
Pocas conexiones van a consumir poca memoria, CPU o ancho de banda, pero tal vez no sean suficientes para atender muchas consultas en paralelo.
Muchas conexiones van a consumir mas memoria, CPU o ancho de banda. Si bien puede permitirnos atender mas consultas en paralelo, podría agotar los recursos de la dependencia y dejarla inoperante.
Abrir y cerrar conexiones constantemente (Handshake y Closure Handshake) también va a generar consumo de recursos ya que esto implica realizar varias operaciones que consumen tiempo.
Limite de Conexiones
No se pueden crear todas las conexiones que uno desee.
Todos los dispositivos tienen un limite de conexiones máximas que pueden abrir para establecer una conexión y aceptarla, tanto del lado del cliente como del lado del servidor.
Este limite suele estar definido por el sistema operativo o la aplicación.
Si esos limites se exceden, esto puede provocar que se rechacen nuevas solicitudes de conexión o que se produzcan bloqueos, conflictos o errores en nuestra aplicación o en la dependencia.
¿Qué es un Connection Pool y cómo nos puede ayudar a manejar múltiples conexiones simultáneas?
Un Connection Pool nos ayuda a manejar la cantidad de recursos y el limite de conexiones disponibles de forma optima creando un conjunto de conexiones que se mantienen abiertas contra una dependencia y que pueden ser reutilizadas para realizar múltiples operaciones.
En lugar de establecer una conexión con una dependencia cada vez que se necesita realizar una consulta o una actualización, se mantiene un número de conexiones abiertas en el pool y se usan según se requieran.
Esto mejora el rendimiento y la eficiencia de las aplicaciones, ya que al reutilizar las conexiones evita el costo de abrir y cerrar conexiones constantemente tanto del lado del cliente como del servidor.
¿Como funciona un Connection Pool?
Para explicar como funciona un Connection Pool, voy a utilizar como ejemplo una fila del supermercado, donde hay una única fila de clientes y varios cajeros para atender.

Como se ve en la imagen, tenemos un grupo de 4 cajeros y una única fila con clientes.
Cuando un cajero se libera, atiende al siguiente cliente en la fila.
El Connection Pool esta representado por el grupo de cajeros que atiende a los clientes y cada cliente representa una consulta.
Esto permite mantener ocupadas todas las cajas con un flujo constante de clientes.
Volviendo a una aplicación, un Connection Pool funciona de la misma manera:
Llega una peticion para hacer una consulta a una dependencia
La aplicacion le pide al Connection Pool una conexion que este libre
El Connection Pool le entrega una conexion libre para que realice la consulta
La aplicacion realiza la consulta
La aplicacion devuelve la conexion al pool para que la proxima peticion que reciba pueda utilizarla
¿Qué ventajas y desventajas tiene usar un Connection Pool?
Ventajas
Reduce el costo de abrir y cerrar conexiones constantemente, lo que mejora el rendimiento y la eficiencia de las aplicaciones que acceden a una dependencia.
Permite reutilizar las conexiones existentes en lugar de crear nuevas conexiones para cada operación con los datos, lo que ahorra tiempo y recursos.
Facilita la adaptación a las condiciones dinámicas de la aplicación y una dependencia, ya que el pool puede ajustar el número de conexiones según la demanda o la disponibilidad.
Desventajas
Puede ser complicado encontrar la configuración optima del tamaño del pool, el timeout y el ciclo de vida de las conexiones.
Puede aumentar el riesgo de seguridad o privacidad de las conexiones, ya que las conexiones abiertas pueden ser vulnerables a ataques o filtraciones de información. Siempre es recomendable usar conexiones seguras para minimizar este tipo de riesgos.
¿Cuales son los errores mas comunes al usar un Connection Pool?
Estos son algunos de los errores mas comunes al usar un Connection Pool:
Usar un tamaño de pool demasiado grande, lo que puede consumir recursos innecesarios o saturar una dependencia.
Usar un tamaño de pool demasiado pequeño, lo que puede provocar que se rechacen solicitudes o que se generen tiempos de espera innecesarios bloqueando la aplicación.
No configurar correctamente el timeout del Connection Pool, lo que puede provocar que se bloqueen los hilos de la aplicación o se generen errores.
No cerrar o liberar las conexiones correctamente, lo que puede generar fugas de memoria (memory leaks), bloqueos o inconsistencias de datos. Es importante cerrar o liberar las conexiones cuando no se necesitan, para que puedan ser reutilizadas por otros hilos de ejecución o liberar los recursos asociados.
No validar las conexiones adecuadamente, lo que puede provocar errores o mal funcionamiento de las operaciones con los datos. Es conveniente validar las conexiones antes de usarlas, para comprobar que están en buen estado y no han caducado o se han desconectado.
¿Como definir el tamaño optimo de un Connection Pool y qué factores hay que tener en cuenta?
No existe una fórmula única para calcular el tamaño óptimo de un pool, ya que depende de cada caso y de las características de la aplicación y la dependencia.
Para poder definir el tamaño correcto para un Connection Pool hay que analizar los siguientes factores con respecto a una aplicación y la dependencia que se va a usar:
La demanda de conexiones, que depende del número y la frecuencia de las operaciones con los datos que realiza la aplicación. Si la demanda es alta, se necesita un pool más grande para evitar tiempos de espera o rechazos de solicitudes. Si la demanda es baja, se puede usar un pool más pequeño para ahorrar recursos.
La disponibilidad de conexiones, que depende del límite máximo de conexiones que puede aceptar la dependencia. Si el límite es alto, se puede usar un pool más grande para aprovechar la capacidad de la dependencia. Si el límite es bajo, se debe usar un pool más pequeño para evitar saturar la dependencia.
El rendimiento de las conexiones, depende de la velocidad y la fiabilidad de las operaciones con los datos que se realizan con una dependencia. Si el rendimiento es alto, se puede usar un pool más pequeño para reducir el costo de mantener las conexiones. Si el rendimiento es bajo, se puede usar un pool más grande para compensar el tiempo de las operaciones.
Todos estos factores se pueden visualizar utilizando métricas de alguna herramienta de monitoreo como CloudWatch, DataDog, Grafana, etc.
Adicionalmente realizar un Test de Carga (Load Test) nos permite saber si el tamaño del Connection Pool es adecuado cuando la aplicación recibe mucho trafico.
Conclusiones
Un Connection Pool nos permite mantener activas un grupo de conexiones entre una aplicación y una dependencia.
El uso del Connection Pool permite optimizar la conectividad y el uso de recursos de una aplicacion y de las dependencias.
Si utilizamos un Connection Pool grande vamos a desperdiciar recursos y saturar a la dependencia.
Si utilizamos un Connection Pool pequeño es posible que la aplicación demore en responder o se genere un Timeout.
Es importante contar con herramientas de monitoreos y hacer un test de carga para saber si el tamaño del Connection Pool es optimo.